What Does It Mean to Evaluate an AI Model?
Understanding AI Evaluation and AI Validation in Modern Enterprise Systems
Artificial Intelligence is rapidly becoming part of everyday business operations. From customer support automation and fraud detection to healthcare diagnostics and enterprise decision-making, organizations are increasingly relying on AI systems to improve efficiency and scale operations.
But as AI adoption accelerates, one critical question continues to grow in importance:
“How do businesses know whether an AI model is actually reliable, accurate, and safe to use?”
This is where AI evaluation becomes essential.
For many organizations, building an AI model is only the first step. The real challenge lies in understanding how that model behaves in real-world environments — especially when decisions, customer experiences, compliance requirements, and operational risks are involved.
What Is AI Evaluation?
In simple terms, AI evaluation is the process of testing and measuring how well an AI model performs under different conditions.
Just like software applications undergo quality testing before deployment, AI systems also require structured analysis to determine whether they are accurate, reliable, consistent, safe, fair, and ready for production use.
Modern AI models can produce highly intelligent and convincing outputs. However, convincing does not always mean correct.
Research from IBM explains that AI systems can sometimes generate fabricated or misleading responses — commonly referred to as AI hallucinations. These inaccuracies may appear confident and believable, making them difficult to identify without proper AI validation mechanisms in place.
Why AI Evaluation Matters More Than Ever
Unlike traditional software systems, AI models are probabilistic. This means that the same input may generate different outputs, performance can change over time, and unexpected edge cases may produce unreliable behavior.
Without structured AI evaluation, organizations risk deploying models that could produce inaccurate recommendations, biased outputs, or operational failures.
A recent study published on arXiv identified a growing rise in fabricated AI-generated citations and references in enterprise and academic workflows after widespread Large Language Model adoption.
AI Evaluation vs AI Validation
AI evaluation focuses on measuring model performance through testing, benchmarking, and scenario analysis.
AI validation focuses on determining whether the AI system is suitable for real-world deployment and governance readiness.
Together, AI evaluation and AI validation help organizations build AI systems that are not only powerful, but also dependable and trustworthy.
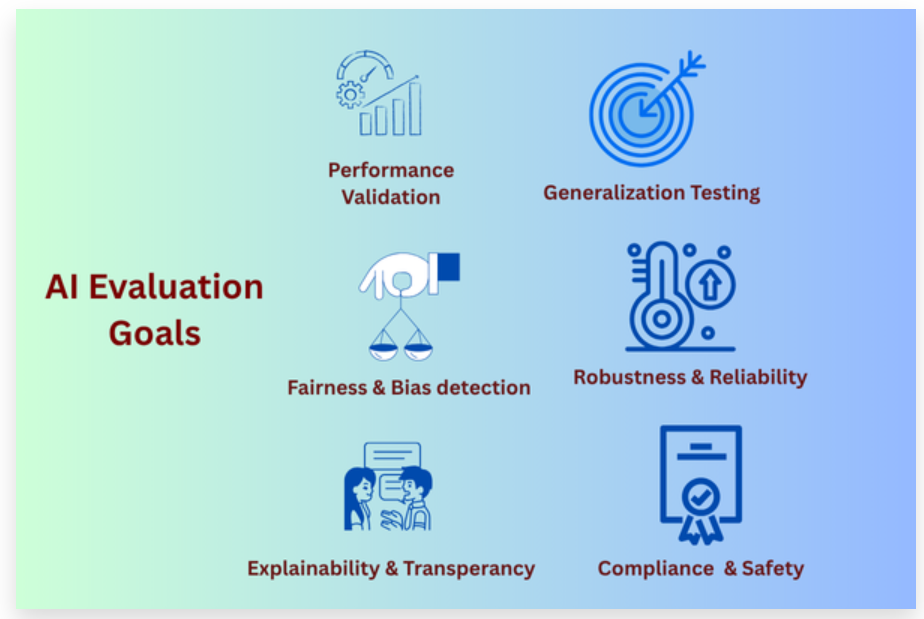
What Exactly Gets Evaluated in an AI Model?
Modern AI systems are evaluated across multiple dimensions depending on the business use case and deployment environment.
• Accuracy
• Consistency
• Hallucination Detection
• Bias Detection
• Safety Testing
• Edge Case Performance
• Explainability
• Compliance Readiness
Scientific Evidence Is Already Highlighting AI Risks
The growing emphasis on AI evaluation is not based on theory alone. Researchers and enterprise technology leaders are increasingly identifying reliability concerns associated with AI systems.
Governance-focused studies highlight how hallucination, bias, and model drift are now central concerns in enterprise AI governance strategies.
Enterprise AI research also emphasizes that unmanaged hallucination risks in Large Language Models can directly affect operational reliability, compliance, and customer trust.
A Real-World Example of AI Evaluation
Imagine an enterprise deploying an AI-powered customer support assistant.
Initially, the system appears highly efficient:
• Faster response times
• Reduced support workload
• Automated ticket handling
• Improved operational scalability
But over time, hidden problems begin to emerge:
• Inconsistent responses to customers
• Fabricated policy explanations
• Incorrect troubleshooting guidance
• Failure during unusual scenarios
• Unsafe or misleading recommendations
Without structured AI evaluation, these issues may remain undetected until they begin affecting customer trust and business operations.
Why Businesses Are Investing in AI Validation Services
As AI ecosystems become more complex, organizations are realizing that traditional software testing approaches are no longer sufficient.
Many enterprises are now prioritizing:
• AI reliability testing
• Hallucination detection
• Bias monitoring
• Governance readiness
• Compliance alignment
• Continuous model evaluation
At Openvals, the focus is on helping organizations build confidence in AI systems through structured AI evaluation methodologies designed for real-world enterprise deployment scenarios.
The Future of AI Depends on Trust
The AI industry is entering a new phase.
The conversation is no longer just about building more advanced AI systems.
The real challenge now is ensuring those systems are reliable, explainable, safe, governed responsibly, and trusted by businesses and users alike.
This is why AI evaluation and AI validation are rapidly becoming foundational pillars of responsible AI adoption.
Because in the future, the most successful AI systems will not simply be the most intelligent.
They will be the most trusted.
Scientific References
· IBM — What Are AI Hallucinations?
https://www.ibm.com/think/topics/ai-hallucinations
· arXiv — LLM Hallucinations in the Wild
https://arxiv.org/abs/2605.07723
· ScienceDirect — AI-Driven Cybersecurity Hallucination Risks
https://www.sciencedirect.com/science/article/abs/pii/S0045790625002502
· EC-Council — Bias, Drift, and Hallucination Governance
https://www.eccouncil.org/cybersecurity-exchange/responsible-ai-governance/bias-model-drift-hallucination-mapping-ai-risks-to-governance-controls/
· EY — Managing Hallucination Risk in LLM Deployments
https://www.ey.com/content/dam/ey-unified-site/ey-com/en-gl/technical/documents/ey-gl-managing-hallucination-risk-in-llm-deployments-01-26.pdf
Prepared for Openvals | https://openvalidations.com